
Data driven testing, или DDT-подход (еще встречается определение “параметризованное тестирование”) — популярная вещь в тестировании.
Подробнее о параметризации тестов можно почитать здесь, а пока продолжим.
- DDT в Selenium
- Каким бывает DDT-фреймворк на основе Selenium
- Плюсы и минусы DDT-фреймворка
- Имплементация DDT-фреймворка на основе Selenium при помощи библиотеки Apache POI
- Инструменты для сборки DDT-фреймворка с Apache POI
- Тестовый сценарий
Если коротко, данные для тестов хранятся в табличном формате, во внешних электронных таблицах, в 99% случаев в Excel-формате (поэтому иногда бывает еще одно определение — “table-driven testing”).
В DDT-подходе к тестированию, QA-команда выполняет функциональные тесты на большом наборе данных, получаемых из внешних источников.
DDT-подход обычно применяют, когда возникают такие «челленджи»:
- Сложность скриптов: тестовые данные из одних скриптов нужны для выполнения других скриптов
- Скрипты используют данные из разных тестовых окружений
- Работа с тестовыми данными подразумевает привлечение большого количества тестировщиков, затрачивается много времени и усилий
Для QA-команды, которая выполняет свои тесты на огромных массивах данных и в нескольких окружениях, DDT-методология становится попросту необходимой. Она значительно снижает стоимость создания и обслуживания больших массивов данных. При изменении бизнес-логики приложения, просто меняются эти массивы, не затрагивая “более высокие” участки кода. Далее, DDT это более-менее удобный анализ данных, что важно в некоторых специфических окружениях. Итак, посмотрим, как такая методология работает в самом популярном из фреймворков.
DDT в Selenium
Перед тем как обсуждать как работает DDT в нашем любимом Selenium, надо кратко уточнить для новичков, что такое фреймворк для автоматизации. Это набор инструментов для автоматизации тест-кейсов. Как правило не один инструмент, а объединенный набор инструментов и процессов, применяемых параллельно. Фреймворк автоматизации — это сочетание модулей (например, тестовые данные, библиотеки, зависимости и другие модули)
Некий “набор правил” в таком фреймворке описывает стандарты кода, техники работы с тестовыми данными, пути хранения и отображения результатов тестов, и репозитории объектов.
Типы фреймворков автоматизации в Selenium:
- Data-driven-фреймворки. Как уже должно было быть понятно, предназначены для логического “отделения” тестовых данных от тестовых скриптов. Один тестовый скрипт может запускать (последовательно или параллельно) внешний большой набор тестовых данных, вместо hard-coded тестовых данных.
- Keyword-driven-фреймворки. В рамках этого подхода “ключевые слова” загружаются из Excel-таблицы. Эти ключевые слова описывают набор действий, проводимых на каждом этапе. Подробнее об этой методологии можно почитать например здесь. Или здесь.
- Гибридный фреймворк. Это комбинация двух вышеупомянутых подходов. В нем и ключевые слова, и тестовые данные — подтягиваются извне, в табличной форме.
Каким бывает DDT-фреймворк на основе Selenium
Когда приложение тестируется вручную, скрипты подтягивают данные разных типов из разных массивов. Данные для ручного тестирования хранятся в неких файлах, обычно это Excel-файлы, CSV-файлы, plain-текстовые, или базы данных.
Итак, для автоматизированных тестов на больших наборах тестовых данных применяем репозитории/базы данных/файлы. Всякий DDT-фреймворк на основе Selenium выполняет сценарии, берущие тестовые данные извне, из файлов xls, xlsx, или csv.
Еще раз: DDT-фреймворк на основе Selenium применяет подход четкого логического отделения набора тестовых данных от логики. Поскольку тестовые данные берутся извне и “выделены”, они могут быть модифицированы в любое время без проблем, и без внесения изменений в код скрипта.
Например, если страница логина должна протестироваться на множестве входных данных — комбинациях букв, цифр и спецсимволов, эти тестовые данные удобно хранить в Excel или CSV. Одни и те же наборы данных можно “подавать” в разные тестовые сценарии во время исполнения, и запускать несколько сценариев одновременно.
Selenium — популярный инструмент с открытым исходным кодом, практически стандарт в индустрии по состоянию на 2022 год. Однако он не поддерживает «нативно» так называемые CRUD-операции (create, read, update, delete) на внешних тестовых данных из Excel, CSV, баз данных и т.п. Этот пробел восполнен другими инструментами и API, которые помогают “поставлять” внешние тестовые данные в сценарии в Selenium, и выполнять некоторые другие релевантные операции с тестовыми данными.
В данной статье рассмотрим применение Apache POI. Этот API подключается к Selenium и обслуживает CRUD-операции с внешними данными.
Плюсы и минусы DDT-фреймворка
Плюсы:
- Позволяет тестировать приложение на огромном наборе тестовых данных, с применением регрессионного тестирования
- Тестовые данные могут подаваться извне, собраны в одном файле, и могут храниться отдельно от тестовых скриптов
- Любые внесенные изменения в тестовый скрипт не влияют на тестовые данные; и наоборот
- Один и тот же тестовый метод может запускаться несколько раз с разными тестовыми данными, вместо еще одного создания/вызова тестового метода для разных тестовых данных
- Внешние тестовые данные могут контролироваться/проверяться даже людьми далекими от тестирования/разработки, так что им можно не особо вникать в код
Минусы:
- На чтение данных и их валидацию иногда может потребоваться довольно много времени, в случае реально больших наборов данных
- Объем кода в проекте увеличивается в результате внедрения DDT в Selenium
- С течением времени, код такого DDT-фреймворка может требовать изменения
- Обычно требуется достаточно высокий уровень компетенции для написания DDT-фреймворка
- Для разных тестовых модулей нужно создавать разные файлы с тестовыми данными, что иногда неудобно
Имплементация DDT-фреймворка на основе Selenium при помощи библиотеки Apache POI
Apache POI (“Poor Obfuscation Implementation”) — библиотека с открытым кодом от знаменитой Apache Software Foundation. Один из самых удобных API для сборки DDT-фреймворка на основе Selenium. POI позволяет выполнять операции с Excel-файлами используя Java-приложения, а именно выполнять CRUD-операции чтения и записи в Excel, о которых говорилось выше.
Инструменты для сборки DDT-фреймворка с Apache POI:
- Eclipse, Intellij или другой IDE
- JDK
- Microsoft Excel (ну или LibreOffice)
- Maven-зависимости TestNG, Selenium, Apache POI
Тестовый сценарий: протестировать логин-систему pCloudy (такую) с разными e-mail и паролями:
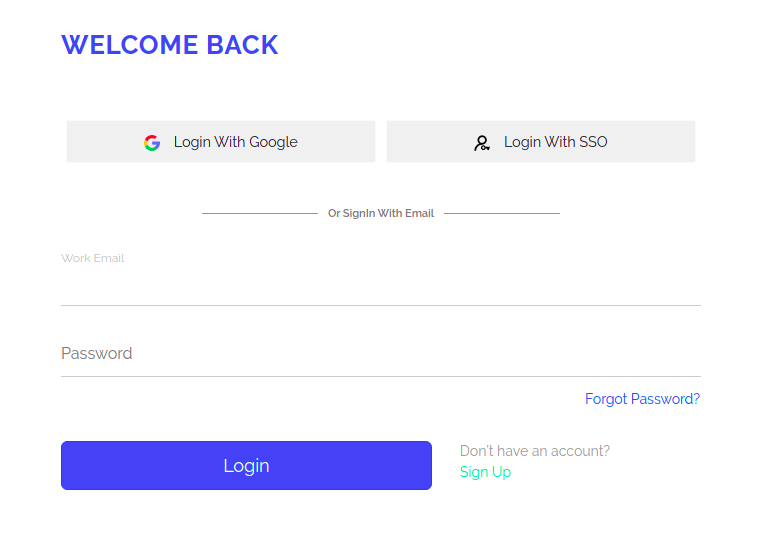
Последовательность действий (сценарий):
- Заход на страницу логинов pCloudy
- Ввод email
- Ввод пароля
- Нажатие кнопки Login
- После логина — получение названия лендинговой страницы
- Запись в Excel-таблицу результатов этого тест-кейса, для соответствующих данных
Перед тем как начинать автоматизацию нашего кейса, сделаем вещь на которой собственно основано DDT — «отделим данные от логики», создадим внешний Excel-файл с парами значений “email/пароль”.
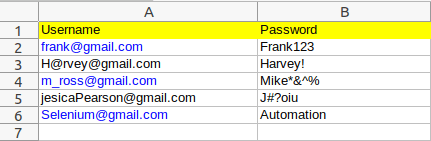
Теперь внимательнее.
Pom.xml. Файл описания объектной модели проекта (Project Object Model), в нем информация по maven-проекту, а также конфигурации — указаны зависимости, плагины, каталог для билдов и т.п. Ниже показана часть зависимостей, нужных для подключения TestNg, Selenium и Apache POI.
<dependencies>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.10</version>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>3.8.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>2.53.1</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.2</version>
<scope>test</scope>
</dependency>
</dependencies>
Класс ExcelOperations. Здесь операции, производимые над нашим Excel-файлом:
- setExcelFile: Инициализация таблицы, прописываем путь к ней.
- getCellData: Считывание тестовых данных (по номеру колонки и строки)
- getRowCountInSheet: Получение количества строк в таблице.
- setCellValue: Запись значений в ячейки (по номеру колонки и строки).
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class ExcelOperations {
private static HSSFWorkbook workbook;
private static HSSFSheet sheet;
private static HSSFRow row;
private static HSSFCell cell;
public void setExcelFile(String excelFilePath,String sheetName)
throws IOException {
File file = new File(excelFilePath);
//Creating object of FileInputStream class to read excel
FileInputStream inputStream = new FileInputStream(file);
//creating a workbook instance (.xls file)
workbook=new HSSFWorkbook(inputStream);
sheet=workbook.getSheet(sheetName);
}
public String getCellData(int rowNumber,int columnNumber){
//getting the cell value from rowNumber and column Number
cell =sheet.getRow(rowNumber).getCell(columnNumber);
return cell.getStringCellValue();
}
public int getRowCountInSheet(){
//getting the count of rows in sheet
int rowcount = sheet.getLastRowNum()-sheet.getFirstRowNum();
return rowcount;
}
public void setCellValue(int rowNum,int columnNum,String
cellValue,String excelFilePath) throws IOException {
//creating a new cell in row and writing value to it
sheet.getRow(rowNum).createCell(columnNum).setCellValue(cellValue);
FileOutputStream outputStream = new FileOutputStream(excelFilePath);
workbook.write(outputStream);
}
}
Класс Constants. Создан для вынесения отдельно констант тестового скрипта, чтобы они могли повторно использоваться в тестовом наборе (сьюте). Основной плюс от создания отдельного класса с константами — если нужны изменения значений, то эти значения могут просто модифицироваться в классе констант, а не в куче мест в коде. Прописываем здесь URL тестового приложения, путь к Excel-файлу, и имя Excel-файла:
ublic class Constants {
public static final String URL = "https://device.pcloudy.com/login";
public static final String TestData_FILEPATH = "/home/ramit/Documents/";
public static final String TestData_FILENAME = "LoginTestData.xls";
}
Класс pCloudyLogin. Главный класс тестового сценария, проверяющего логин-систему pCloudy на парах email/пароль из таблицы. Методы класса excelOperations вызываются в этом классе, они и “подают” данные сюда на обработку, из внешнего Excel-файла. Потом, после выполнения кейса на всех данных в файле, у нас в этот же файл будут дописаны результаты тестов.
import java.io.IOException;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.testng.annotations.AfterClass;
import org.testng.annotations.BeforeClass;
import org.testng.annotations.Test;
import io.github.bonigarcia.wdm.WebDriverManager;
public class pCloudyLogin {
static ExcelOperations excel = new ExcelOperations();
static String excelFilePath
=Constants.TestData_FILEPATH+Constants.TestData_FILENAME;
static WebDriver driver;
@BeforeClass
public void setup()
{
WebDriverManager.chromedriver().setup();
driver = new ChromeDriver();
}
@Test
public void loginTest() throws InterruptedException, IOException
{
driver.get(Constants.URL);
driver.manage().window().maximize();
driver.manage().deleteAllCookies();
excel.setExcelFile(excelFilePath, "LoginTestData");
for(int i=1;i<=excel.getRowCountInSheet();i++)
{
WebElement workEmail =
driver.findElement(By.id("userId"));
workEmail.clear();
workEmail.sendKeys(excel.getCellData(i, 0));
WebElement passWord =
driver.findElement(By.name("password"));
passWord.clear();
passWord.sendKeys(excel.getCellData(i, 1));
WebElement createAccountButton =
driver.findElement(By.id("loginSubmitBtn"));
createAccountButton.click();
String title = driver.getTitle();
if(title.equals("HubSpot Form"))
{
excel.setCellValue(i, 2, "Passed", excelFilePath);
}
else
{
excel.setCellValue(i, 2, "Failed", excelFilePath);
}
}
}
@AfterClass
public void tearDown()
{
driver.quit();
}
}
Запускаем, получаем такой результат:
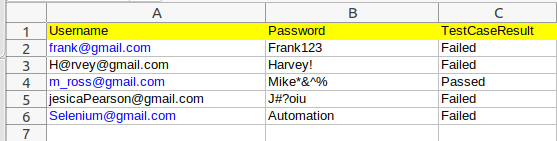
На этом пока все. Если тема заинтересовала, пишите в комментариях!
