
- Метрики
- Узкие места
- Виды тестирования производительности
- Аналогия из жизни
- Инструменты
- Углубляемся
- Производительность фронтенда
- О максимальном количестве пользователей
Все хотят, чтобы программное обеспечение было надежным и использовало минимум ресурсов. Это нефункциональные требования, и их выполнение тоже нужно гарантировать — иначе продукт неработоспособен.
Какие метрики (показатели) производительности имеют значение
Различают три аспекта производительности приложений — от них зависят метрики, указанные далее.
Скорость: Как быстро загружается страница? Скорость — это время отрисовки страницы, время обработки API-запроса или пропускная способность сети при передаче больших файлов.
Стабильность: Нормально ли, стабильно ли ведет себя система, не возникают ли ошибки, мешающие работе? Для оценки стабильности учитывается количество ошибок.
Масштабируемость: Если понадобилось увеличить/расширить/углубить/укрупнить систему, то сколько это будет стоить и сколько времени? А если количество пользователей сервиса удвоится за год? А если в 10 раз? Для оценки масштабируемости нужно проанализировать использование ресурсов под разными нагрузками.
Что будет узким местом
При поиске «узких мест» в производительности обращают внимание на следующие моменты:
Нагрузка на базу данных: Является ли количество запросов, которые посылаются к базе данных, адекватным ее мощностям? Как быстро выполняются запросы?
Пиковое использование памяти: Будет ли что-то «тяжелое» в вычислительном плане? Как это будет масштабироваться? И масштабируется ли вообще?
Аппаратное обеспечение: Хоть и редко, но все еще случается, что именно пропускная способность сети в компании — узкое место; проблема с аппаратным обеспечением мало актуальна для сервисов, выведенных в облако.
Процессор: Когда загрузка процессоров слишком высокая, все развалится на части ?
Место на жестком диске: Лог-файлы и другие файлы, постоянно «пополняемые» приложением, при длительной работе могут занять неисчислимое количество гигабайт на диске.
Соединения: Может быть максимальное количество HTTP-коннектов/коннектов с базой данных. Для Postgres max_connections составляет 100. На nginx обычно ограничение 500 одновременных соединений (источник).
Типы тестирования производительности
Теперь, когда мы знаем потенциальные проблемы, можно подумать о распространенных типах тестирования производительности.
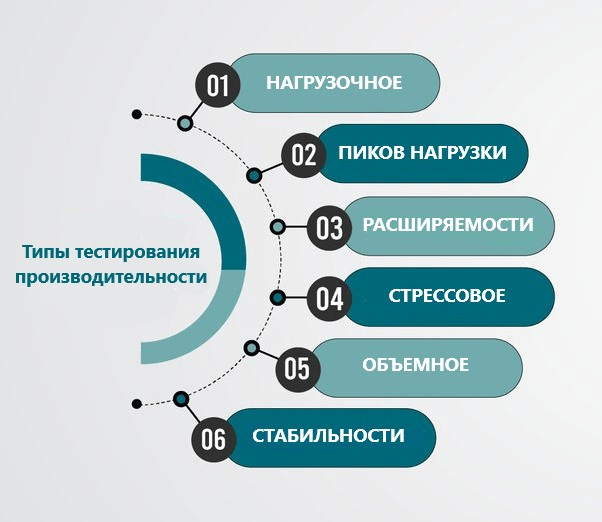
Самыми часто применяемыми являются нагрузочное тестирование, стресс-тестирование и тестирование стабильности (soak testing).
Нагрузочное тестирование
Цель нагрузочного тестирования — увидеть поведение тестируемой системы под ожидаемой нагрузкой. Здесь нет необходимости «ломать» систему, цель тестирования — получить нагрузку, которую приложение ожидаемо будет получать в «часы пик», обычно это рабочие часы. Способно ли приложение стабильно работать при ожидаемой нагрузке?
Аналогия такого тестирования из реальной жизни — экстренные тесты в больницах или аэропортах. Они проводятся для моделирования пиковых ситуаций и проверки, как учреждение будет справляться.
Стресс-тестирование
После нагрузочного тестирования мы будем знать, как система ведет себя при ожидаемой нагрузке. Цель стресс-тестирования — «сломать систему». Приложение тестируется под экстремальной нагрузкой, чтобы увидеть, когда/где/как все ломается, и это называется стресс-тестированием.
Стабильна ли система под нагрузкой? Видят ли пользователи 500-е ошибки? Где верхний предел нагрузки? Восстанавливается ли система после сбоя? А когда происходит сбой, затрагивается ли только доступность системы, да и то легко и временно, или же сбой влияет катастрофически?
Отдельный материал об этом типе тестирования

Тестирование стабильности (Soak testing)
Тестирование стабильности — это попытка ответить на вопрос, как система работает в течение длительного времени. Цель: подтвердить, что система будет работать надежно и долго.
Проблемы, которые будут обнаружены при таком тестировании:
- Исчерпание количества возможных подключений к БД
- Неожиданные перезагрузки серверов
- Утечки ресурсов, например, памяти
- Журналы или другие файлы, которые «раздувают» систему

Аналогия из жизни
Тестирование производительности можно изобразить как тестирование дорожного движения. Люди хотят попасть из пункта А в пункт Б. Им нужно проехать через несколько улиц. Некоторые имеют 5 полос движения, другие — только одну. Одни позволяют двигаться со скоростью 130 км/ч, другие — 50 км/ч. В зависимости от времени может образоваться затор. Если есть узкое место, и машин немного, то, возможно, все будет работать как надо и заторов не будет. Но чем больше машин находится в дорожной системе, тем выше вероятность того, что кому-то придется ждать.
Дорожная система — это ваш веб-сервис. Узким местом может быть блокирующий вызов ресурса, например, транзакция базы данных при высоком уровне изоляции транзакций. Скорость движения — это скорость выполнения транзакции.
Мини-практикум нагрузочного тестирования на примере Locust
Существует масса инструментов для тестирования производительности и профилирования. Мы лишь кратко упомянем несколько, которые мы либо использовали в прошлом (Apache ab, Locust), либо хотим использовать (Apache JMeter, EatX, K6).
Apache JMeter
Apache JMeter — это инструмент нагрузочного тестирования на основе протокола. JMeter имитирует трафик и одновременных пользователей. Он похож на Locust, но работает быстрее.
Apache ab
Apache ab — это инструмент для бенчмаркинга HTTP-серверов. Как таковой, он охватывает гораздо меньшую часть вашей системы, чем Apache JMeter — только HTTP-сервер. Как правило, в большинстве случаев проблемы с производительностью скрыты не в HTTP-сервере.
Locust
Locust — это инструмент тестирования производительности, который позволяет вам определить веб-пользователей, отправляющих HTTP-запросы. Locust автоматически измеряет время отклика и отмечает пройденные/проваленные тесты. Для этого используется файл locustfile.py, который вы просто выполняете с помощью Python. Он выглядит следующим образом:
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 2)
def on_start(self):
self.client.post(
"/login",
json={"username": "foo", "password": "bar"},
)
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
@task(3)
def view_item(self):
for item_id in range(10):
self.client.get(
f"/item?id={item_id}", name="/item"
)
Выполнение locust в папке с файлом locustfile.py запускает локальный веб-сервер, чтобы можно было взаимодействовать с Locust через браузер.

Первое, на что нужно обратить внимание — это статистика. Для каждой эндпоинта вы увидите количество запросов, которые были сделаны к этому эндпоинту. Locust измеряет количество неудачных запросов, время ответа и размер ответа. По времени ответа он показывает минимальное, медианное, среднее, 90%-квантиль и максимальное значения.

На примере выше видно, что эндпоинт /users/registration падал несколько раз. У него также довольно высокое время отклика — как для максимального, так и для 90-процентного значения. Поскольку минимальное время отклика довольно низкое, это может быть индикатором того, что в работе этого конкретного эндпоинта есть узкое место.
Сейчас давайте посмотрим на ошибки:

Locust позволяет вам определять конкретные сообщения через response.failure('failure message') и показывает их здесь. Он также фиксирует более общие проблемы.
C помощью графиков можно определить точки отказа:

Судя по графикам выше, по мере увеличения числа пользователей и количества запросов проходит несколько секунд, пока не увеличится и время ответа.
K6
K6 — это инструмент для нагрузочного тестирования. С помощью него можно писать тесты производительности на JavaScript. Вы можете записывать действия пользователей с помощью плагина Chrome и визуализировать результаты в Grafana. Он выглядит очень гибким, и мы собираемся использовать его на следующем проекте ?
Отдельный материал о тестировании производительности API в K6
Углубляемся в проблемы производительности
После того, как проблемы с производительностью выявлены, нужно что-то с этим сделать. Например, нужно точно определить, откуда исходит проблема, чтобы можно было устранить. Вот некоторые инструменты и методы, которые мы считаем полезными.
Подсчет количества запросов
ORM — это замечательно, но очень легко можно столкнуться с проблемой (n+1)-го числа. Это довольно легко обнаружить, если написать модульные тесты для этих частей и также проверить количество выполненных SQL-запросов.
Изменение архитектуры микросервисов
Если вы используете сервис, который, в свою очередь, использует другой сервис, который использует другой сервис и т.д., то вы получаете время нагрузки от суммы всех сервисов. Это архитектурная проблема. Ее решение может потребовать серьезной переработки всей системы или мощной системы кэширования.
Измерение использования памяти
Когда я работал над задачами в области машинного обучения, иногда случалось, что мне нужно было перемножать большие матрицы в продакшн-системе. Чтобы облегчить себе задачу, я измерял пиковое использование памяти с помощью valgrind и визуализировал его с помощью kcachegrind или memory_profiler в мире Python. Эти инструменты называются «профилировщики памяти», и они могут показать всевозможные вещи, включая графики вызовов, как на изображении ниже:

Установка искусственно заниженных лимитов ресурсов также помогает определять, где память становится проблемой.
Производительность фронтенда
Для поиска проблем с производительностью на фронтенде часто используют Google Lighthouse.
Обычно он запускается из инструментов разработчика Chrome, но вы можете интегрировать Lighthouse в CI и запускать его автоматически при каждом билде!
Какое максимальное количество пользователей ожидается?
Это главный вопрос, на который обязательно нужно найти ответ при тестировании производительности веб-сервиса. Прежде чем назвать число, необходимо знать следующее:
Реалистичный сценарий: Похоже ли поведение виртуальных пользователей на поведение реальных?
Таймауты: Когда запрос считается медленным? Является ли время отклика в 3 секунды нормальным? Является ли нормальным время отклика в 300 секунд? Какие граничные значения скорости ответа?
Заключение
В этом материале мы разобрали разницу между нагрузочным тестированием, стресс-тестированием и тестированием стабильности. Обратили внимание, что важна не только скорость, но и сбои и способность веб-сервиса к быстрому восстановлению. Кратко описали основные инструменты для тестирования производительности. Можно начинать экспериментировать!
